A petición del respetable voy a poner por escrito lo comentado en el Emilcar Daily del 6 de marzo de 2014 sobre renombrar documentos bajo la filosofía Paperless. Lo primero que hay que indicar es que el libro origen de todo esto, Paperless de David Sparks, trata profundamente el asunto y da diversos ejemplos, que quizá resulten más inspiradores que los míos, y seguro más detallados.
Qué nombre poner
Después de mucho experimentar tanto en el trabajo como en casa, he llegado a la conclusión de que la nomenclatura ideal para mí respecto al nombre de un archivo debe incluir de alguna manera la fecha. Los sistemas operativos que manejo (Windows en el trabajo y OS X en casa) ordenan los archivos alfabéticamente por defecto, de manera que si nombro mis archivos comenzando por la fecha en un formato adecuado, obtendré automáticamente un listado de archivos ordenados de más antiguo a más moderno.
Para ello es imprescindible empezar a nombrar el artículo por el año, luego el mes y luego, si es necesario, el día. Veamos varios ejemplos:
20140205 Recibo comunidad propietarios.pdf
2014-02 Factura Movistar.pdf
201403 Pepephone iPad.pdf
Cliente1 1402 Cambio de firmas.pdf
Si separamos los dígitos con guiones tendremos una fecha más fácil de leer pero también un nombre de archivo más largo. En el trabajo siempre anticipo el nombre del cliente a la fecha, porque si no, cuando empiezo a buscar, me sacaría archivos de determinada fecha de varios clientes, y eso no me interesa.
Renombrado automático
Cuando estamos creando archivos de texto u hojas de cálculo, nada más fácil queintroducir a mano el nombre del archivo creado, usando la nomenclatura elegida, pero cuando estamos hablando de documentos escaneados para un sistema Paperless, sin duda Hazel en OS X es nuestro principal aliado. Vamos a ver cómo podemos aprovechar su capacidad de leer en las entrañas del pdf para renombrar correctamente los archivos.
Debemos hacer una regla para cada tipo de documento de los que recibimos habitualmente. Vamos a poner un ejemplo con ticket del supermercado SUPERCOR, perteneciente a El Corte Inglés. Lo primero es escanear con OCR uno de esos tickets y abrirlo en Vista Previa; usando el buscador decidimos que texto es característico de este documento y de ningún otro. En mi caso decido que las cadenas de texto a buscar son SUPERCOR (el producto que tengo contratado) y la fecha del ticket en el formato adecuado, así que determino una regla Content – contains para la palabra SUPERCOR y otra regla Content – contains match para que busque en el documento la fecha con el formato 24/ene/2014.
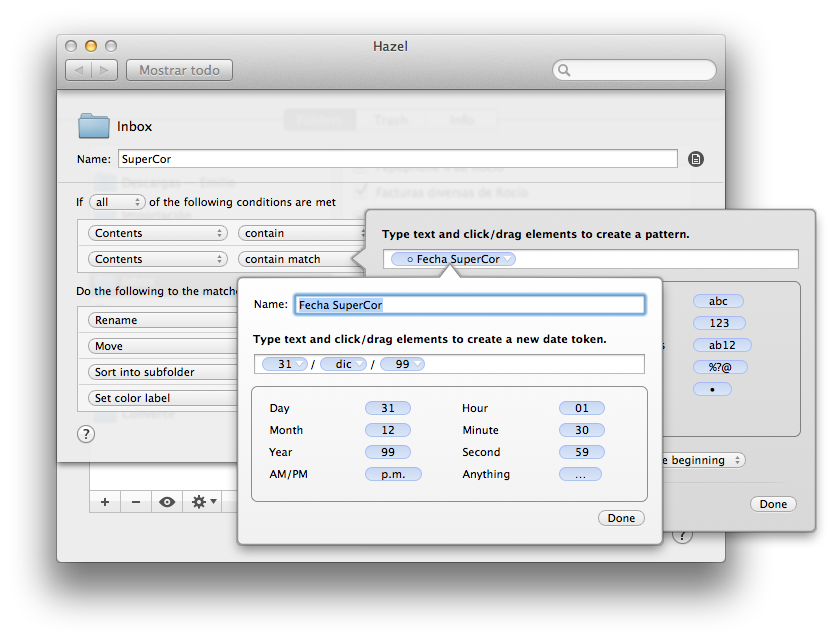
Es imprescindible que estemos seguros de que ningún documento que no sea un ticket de SUPERCOR va a contener estas normas, porque una vez puesto en marcha, el proceso es automático y es muy difícil advertir un error de identificación si no vas abriendo uno por uno cada archivo renombrado.
A continuación, le indico a Hazel que proceda con toda su magia. Una vez que Hazel ha detectado una cadena de datos coincidente con un formato (en este caso la fecha) ya podemos usar esos datos como queramos. Por ejemplo, si ha detectado el mes como feb en el documento, podemos decirle que use el número del mes (02) para renombrarlo, y cosas así. En este caso he optado por la función Rename usando el patrón de la fecha reconocida, pero cambiando el orden y alterando la nomenclatura, de manera que si Hazel ha detectado la fecha 24/ene/2014, mi documento se llamará 20140124 Compra SuperCor.pdf. Podría haber hecho igual que se llamara 14-01 supercor.pdf o cualquier variante de la fecha detectada, a mi antojo.
Todo este proceso tiene lugar en la carpeta donde opera la regla, en mi caso en la carpeta a donde van a parar todos los pdf que escaneo. Ahora toca moverlo, y le indico a Hazel que mueva ese pdf a la carpeta Compras, y que lo ordene en una subcarpeta que se llamará de nuevo en función de la fecha detectada, en mi caso es carpeta se llama 2014-01 usando el año y mes detectado en el ticket. También van a parar ahí tickets de otras tiendas. Para rematar, le pongo una etiqueta violeta, porque me gusta.

La única pega de este sistema es que hay que crear una regla específica para cada tipo de documento habitual que vayamos a escanear. Sin duda un trabajo menos tortuoso que tener que renombrar a mano uno por uno todos los documentos entrantes.
Deja una respuesta